产品详情
长安汽车智能化研究院是中国长安汽车集团有限责任公司旗下专注于汽车智能化技术探讨研究和创新的研发机构。其愿景是通过持续创新和技术突破,实现汽车智能驾驶、智能网联和智能交通的全面发展,提供更安全、更便捷、更智能的出行体验,并成为中国汽车智能化领域的领军企业。
智能化是汽车工业发展近百年来对汽车功能的一次重新定义,它旨在利用大数据、人工智能、云计算、物联网等数字技术,对汽车设备和系统的运作时的状态进行全方位的感知、分析、决策和控制,来提升汽车的安全性、舒适性、便捷性和节能性。因此,对于广大汽车企业而言,实现汽车智能化的关键之一,是需要首先建立起一个稳定、高效的数据平台,以承载和利用海量的车联网数据。
以长安汽车智能化研究院为例,其承担着整个长安汽车集团车联网数据的汇聚、处理和应用工作,并已在业务指标分析、质量管理系统、智慧能耗、智能诊断、智慧运营等重点场景实现一定的数据应用。而此前支撑这些应用的,是长安汽车智能化研究院基于Lambda架构,采用Flink、Hive、Iceberg、Doris等多个开源大数据组件组装而成的数据平台,如用Spark做离线数据的加工,Doris做实时数据的查询,并以Iceberg做数据湖支持规模数据的写入,以两个独立的通道来支持数据的离线加工和实时业务。这也是业界主流的数据架构,承载了长安汽车一直以来的数智化发展。
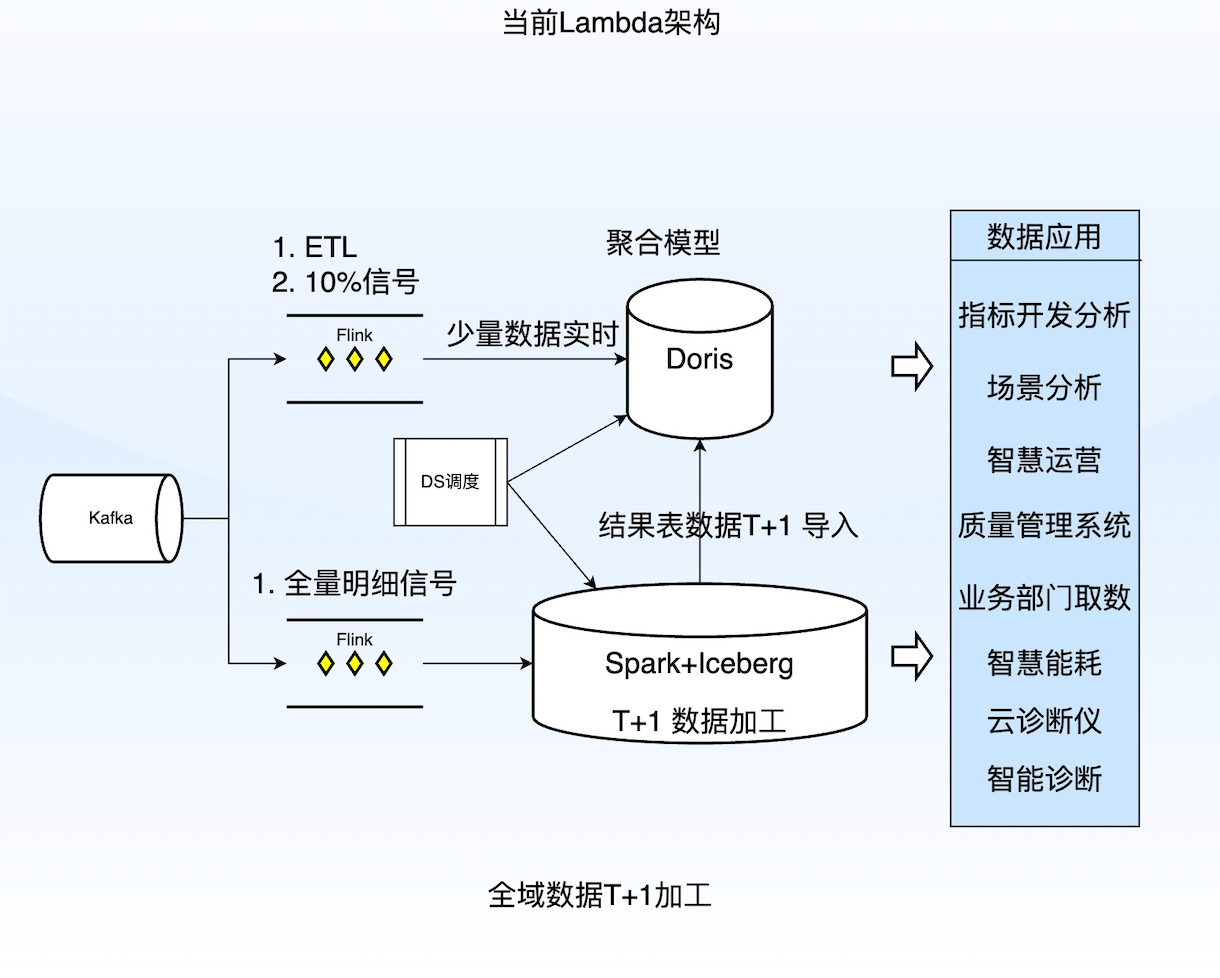
然而,在近几年汽车销量迅速增加,和汽车智能化水准不断提升的背景下,长安汽车原有的数据平台逐渐难以应对规模迅速膨胀的车联网数据,其面临的挑战主要集中在以下几个方面:

1) 难以承接高吞吐,大规模数据的实时写入和处理。为了实现智能化,汽车的车门、座椅、刹车等设备上会被设置大量的传感器,每个传感器会收集一种或多种类型的信号数据,之后再被汇聚和做进一步加工处理。具体到长安汽车,其当前需要处理信号数据达到上千种,并且随着其汽车智能化水平的不断的提高,预期在未来需要处理信号数据将达到上万种;与此同时,长安汽车近年来销量持续增长,市场保有量逐步的提升,当前已经需要支持400万辆车的连接,预计到2025年需要连接上千万辆。
信号数和汽车保有量的快速增加,以及车联网数据本身就具有高采集密度的特点,首先给长安汽车带来的就是数据写入的挑战。一方面,长安汽车车联网数据的每秒的吞吐量已达数百万级TPS,预期很快就会达到千万级TPS;另一方面,长安汽车当前每天产生的车联网数据规模已达到几十TB,未来每天产生的数据可能会数倍于这个量级。
但长安汽车原有的数据平台通过组合多个数据通道产品,如Kafka -Flink- Iceberg/HDFS形成复杂的数据加工链路,来解决数据入湖仓的问题,实时性不足,且过程需要做非常多的预计算和处理。原先的数据平台无论在系统能力,还是资源消耗层面已经疲于应对当前这种规模的数据写入,更不必说未来数倍规模增长的数据。
2)难以支撑准确及时的数据查询分析需求。在车联网场景的数据应用中,快速给出各种分析结果是保障服务有效性的前提。例如在智能诊断中,车企需要近实时地收集相关信号数据,并快速定位故障原因。但车联网数据的处理存在很多特殊性,在很多场景下,原有数据平台在性能和成本等方面,不能支持实时查询和分析的更高需求,包括:
Doris链路通常只适合对有限列的信号数据来进行实时处理,如果用Doris对车联网全量信号数据来进行分析,成本会非常高昂。
车联网数据的采集会存在很多延迟的情形,如在地下车库等信号不佳的地区,数据回传存在一段时间差,导致需要重新扫描一定时间内的历史数据,并进行写入更新。而如果用原有的数据平台频繁地进行延迟数据更新,会带来额外的高成本。
随着汽车上传感器数量的增加,数据平台需要写入和处理的信号类型数据会一直在变化,也即数据的schema会出现变动。但原有的数据平台不能灵活高效地支持这种信号列可变的数据处理。
车辆静置或设备状态没发生改变期间,平台采集了大量重复的信号数据,如对大量重复数据来进行计算,不仅会大幅度降低计算性能,同时也造成了较高的资源浪费。
3)难以负担不断攀升的数据存储和计算成本。长安汽车数据量的快速攀升,以及逐渐要求对数据来进行全量写入和计算的要求,给其带来了逐渐高昂的数据存储和计算成本。但与此同时,原有数据平台却不能很好地针对车联网数据的特点进行针对性地的成本优化,例如:
原有数据平台采用Json格式对车联网数据来进行存储,无法对数据来进行有效压缩,以此来降低存储和计算成本。
原有数据平台在多套引擎中传输和同步数据,造成了数据存储的冗余,以及额外的ETL作业和计算成本。
原有数据平台采用存算一体的架构,无法针对存储和计算资源需求,分别进行弹性扩展。
4)难以应对多组件带来的使用和运维的复杂性。为了高效处理车联网数据,长安汽车智能化研究院曾尝试在原有的数据平台架构基础上,引入新的大数据组件,修补之前遇到的问题。然而,不断堆叠的各类大数据组件,让整个平台的使用和运维很复杂。因为在组装式的架构中,每个引擎都是独立开发和运维的,它们之间有几率存在不同的系统模块设计优化方向。当业务需要调整引擎之间的配置时,例如重新平衡数据新鲜度、性能和成本之间的关系,有必要进行复杂的修改和重复开发工作。这增加了调整的复杂性和耗时,使得数据架构调整的周期较长,无法应对快速变化的业务需求。
构建Lakehouse一体化数据平台,获取数据处理时效性、性能、成本和易用性的最优解
为了支撑海量车联网数据的写入和处理,并在数据处理的时效性、性能、成本和易用性等方面获得显著优化,以应对长安汽车在当前以及未来的汽车智能化需求。长安汽车智能化研究院经过反复的探讨和验证,最终发现如果继续基于开源路线,采取对原有数据平台打补丁的方式,无法从根本上解决以上问题,因此迫切地需要引入一套针对物联网数据处理的全新的数据平台架构和技术体系。最终,长安汽车智能化研究院基于云器科技自研的Lakehouse一体化数据平台,为其痛点需求找到了最佳解决方案。
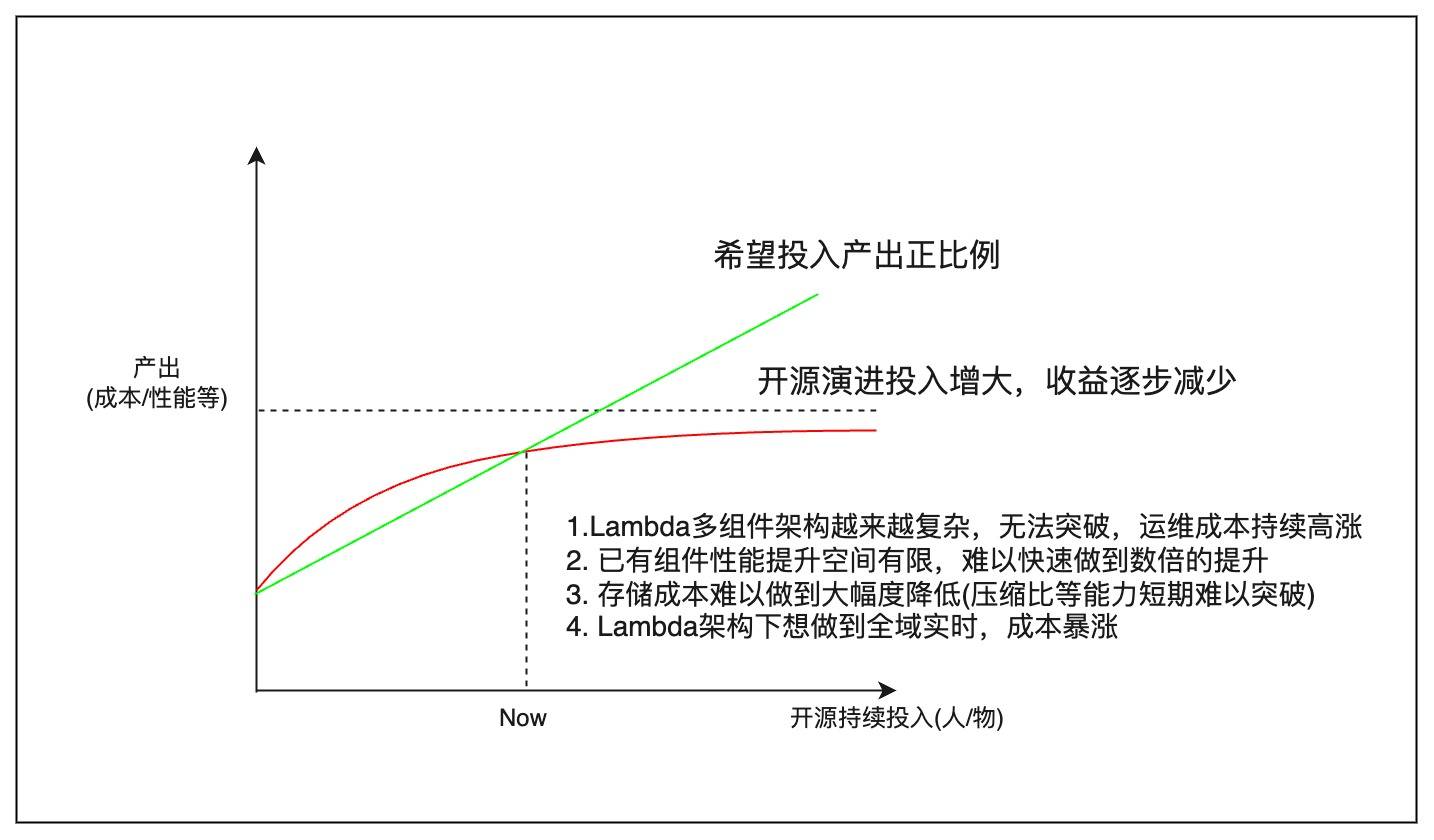
云器科技成立于2021年,是一家多云及一体化的数据平台提供商,小组成员主要由来自阿里云、字节、微软、Oracle等国内外顶尖云计算与大数据企业的资深技术人员组成。云器科技自研的Lakehouse一体化数据平台,能够让数据平台架构更简单、数据更开放、分析更灵活。
图4:长安汽车基于云器科学技术产品升级后的Lakehouse一体化数据平台架构(来源:长安汽车智能化研究院)
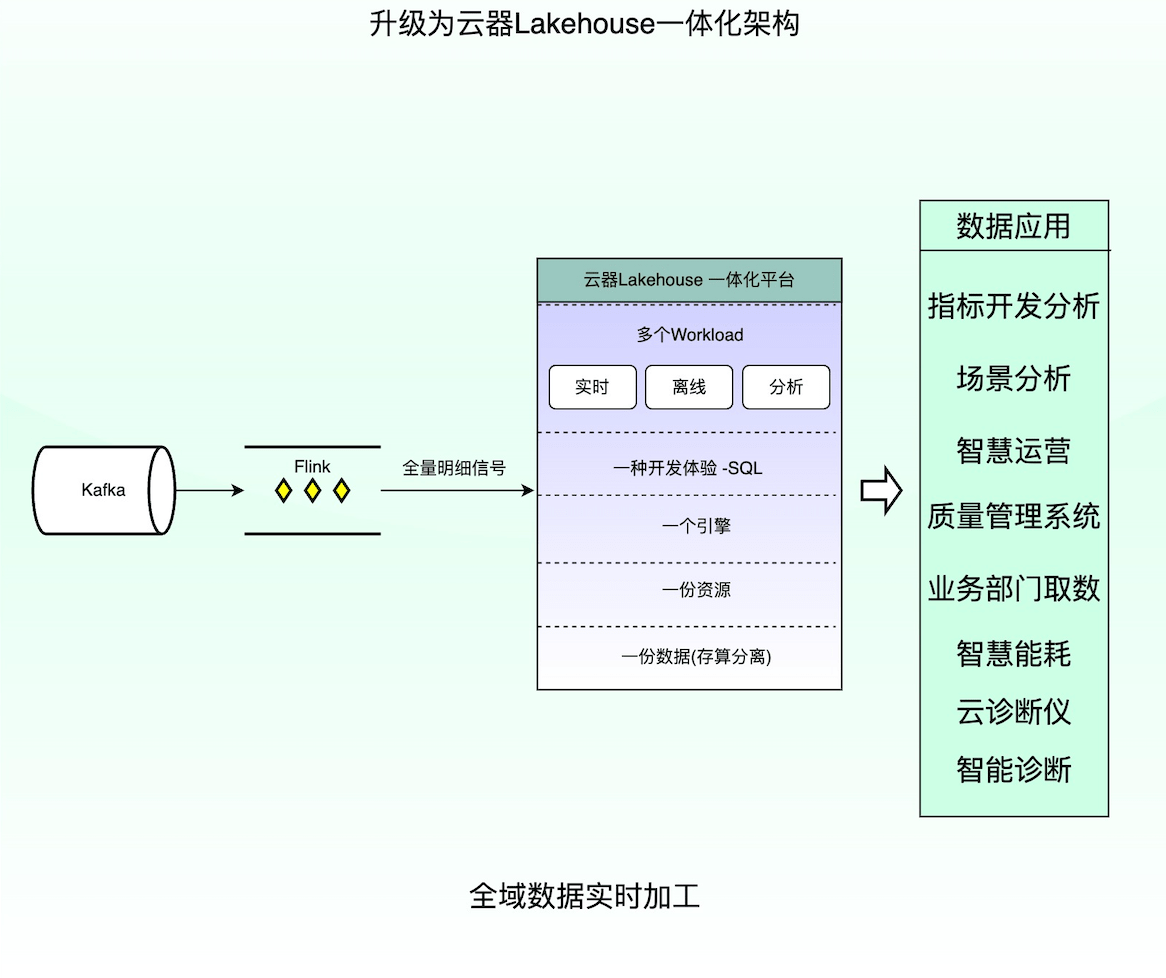
长安汽车基于云器科学技术产品升级后数据平台采用了一体化的架构,以及极具创新性的全数据链路实时增量计算模式,结合多重技术优化,让长安汽车能够以较低的成本应对超大规模的数据实时写入和及时分析。具体而言,新的数据平台在以下多方面做了显著的技术创新,来实现这一目标。
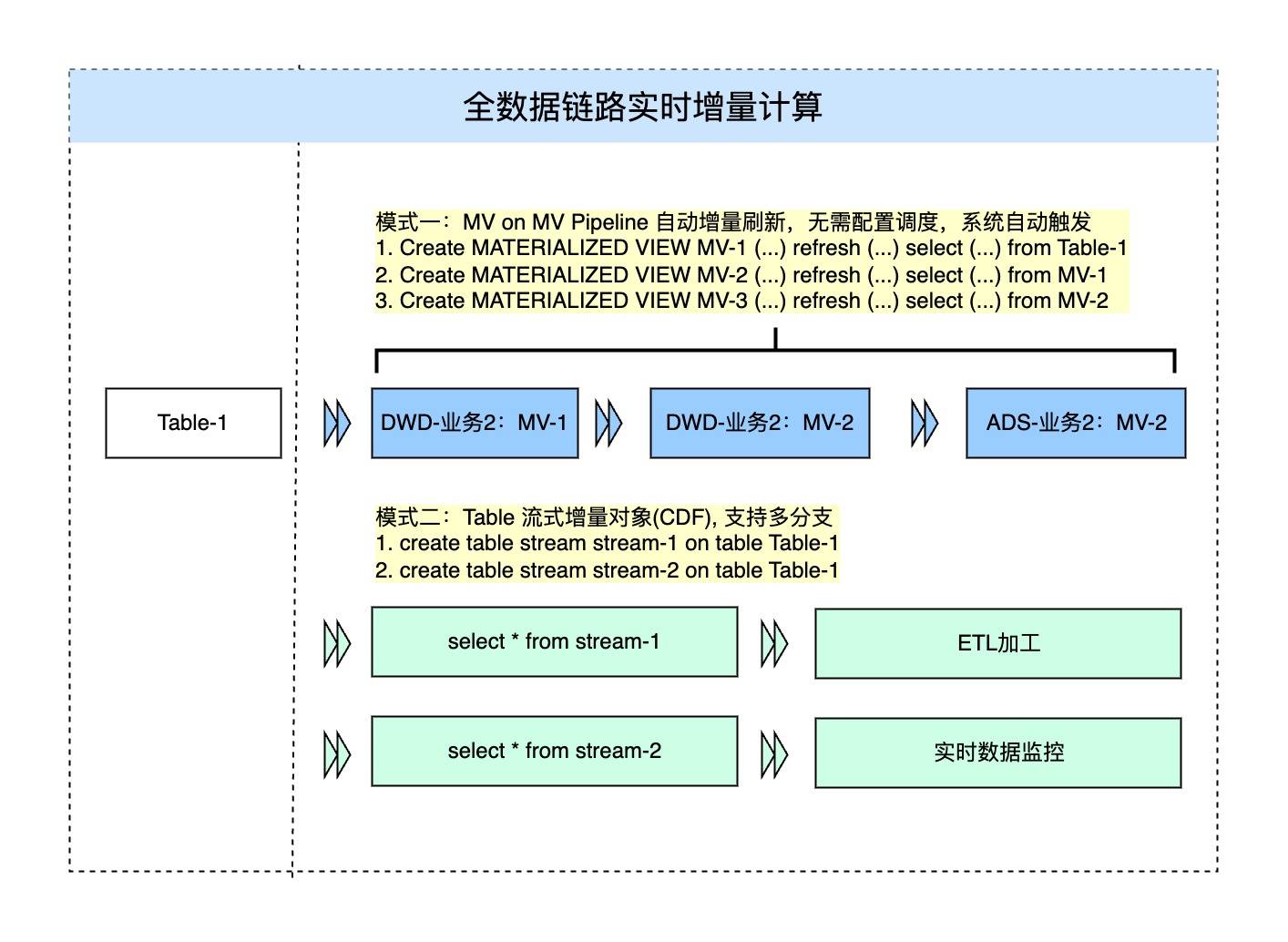
图5:长安汽车构建的全数据链路实时增量计算模式(来源:长安汽车智能化研究院)
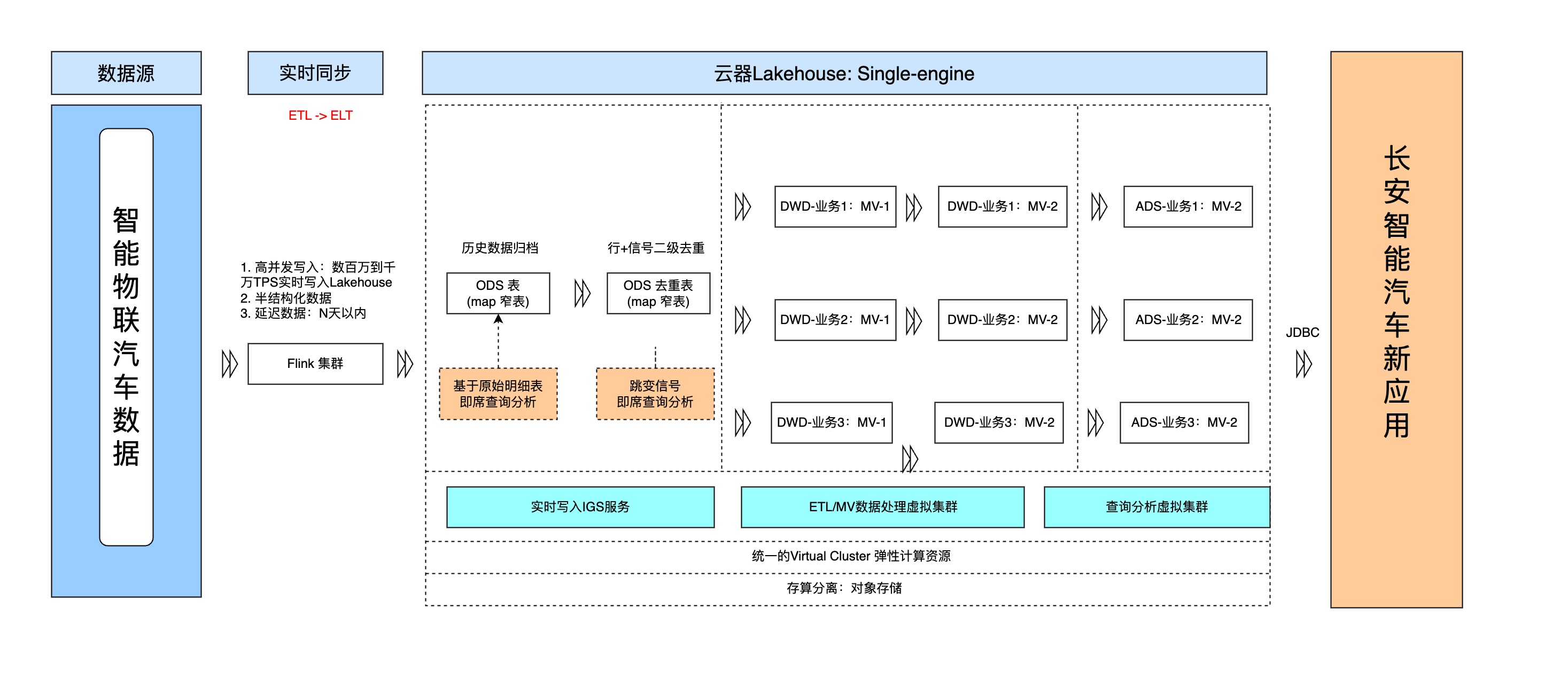
1) 一体化架构。新的数据平台以一套引擎,统一离线、实时、交互式分析三种计算形态,统一数据存储和管理,统一数据开发、统一数据服务。长安汽车因此能在一个一体化的数仓架构中用一套SQL同时开发实时、离线和多维分析任务,降低了开发难度和运维成本,也减少了数据冗余和数据不一致等问题。
2) 增量计算。新的数据平台将一天内产生的车联网数据拆分为小份多批次,如每5分钟一次将增量数据实时写入平台,并来加工处理,避免全量数据计算给系统带来了的负载压力;同时,系统能根据过滤规则在增量数据中只选择与分析需求相关的数据来进行计算,避免数据更新时对全量数据来进行扫描带来的额外计算时间和成本。因此,增量计算有效解决了长安汽车面临的几点问题:
3) 高并发写入。新的数据平台采用读写分离的架构,支持高吞吐upsert及数据入湖仓后的快速增量数据识别与自动化更新处理。同时,为保障数据能够以千万级TPS实时写入,云器在科技还在以下方面做了针对性的优化:
通过独立的实时数据接入服务Ingestion Service,在读写分离架构下,为数据写入分配独立的计算资源,让平台具备高吞吐数据写入的能力;
采用新的数据存储格式Map对原始数据来进行压缩,并采用多种索引与文件组织技术进行存储优化;
将实时写入的数据与已经写入的数据进行统一建模管理,但仅对增量对象进行高效计算,充分的利用集群中空闲资源进行数据整合。

4) MV on MV与Table Stream结合的新数仓模式。新的数据平台采用在物化视图之上再构建物化视图的方式,即MV on MV,构建了一种新的数仓模式,可实现一键创建数据加工处理的Pipeline,自动对新增数据来进行加工处理。大幅度降低数据开发工作成本的同时,也提高了数据处理的效率。具体而言,这种新数仓模式的主要特征有:
数仓创建可以直接用SQL表达,结合其他的计算脚本形成统一的编程语言;
MV的自动管理和维护,无需配置调度,系统自动依据数据新增行为自动触发,同时可结合SQL优化技术对于新提交数据做队列或重跑处理;
所有的资源调度采用统一调度,由于任务调度和作业调度都统一在一个资源池里,避免分开调度带来的不一致问题。
同时,由于在部分分析场景,用MV on MV的方式,SQL语句会很复杂,且用全量数据的处理逻辑不够灵活。新的数据平台提供了更灵活易用的Table Stream,即Table流式增量对象(CDF)模式。具体而言,用户都能够针对每一张表创建Table Stream,实现定时处理某一类型的增量数据;并且Table Stream能支持多分支的增量数据消费,即一份增量数据能够适用于如ETL加工、质量监控等多个数据处理链路。从而极大提高数据处理的灵活性和时效性。
5) 数据去重。云器科技针对车联网场景存在大量重复数据的问题进行了创新性的优化,首先是进行行级去重,去除车辆设备状态未变化期间产生的重复行级数据,其次在行级去重的基础上再进行信号去重,去除行之间重复类型的信号数据。通过数据去重降低数据量,大幅度的提高了下游任务的计算性能,同时也节省了计算资源。
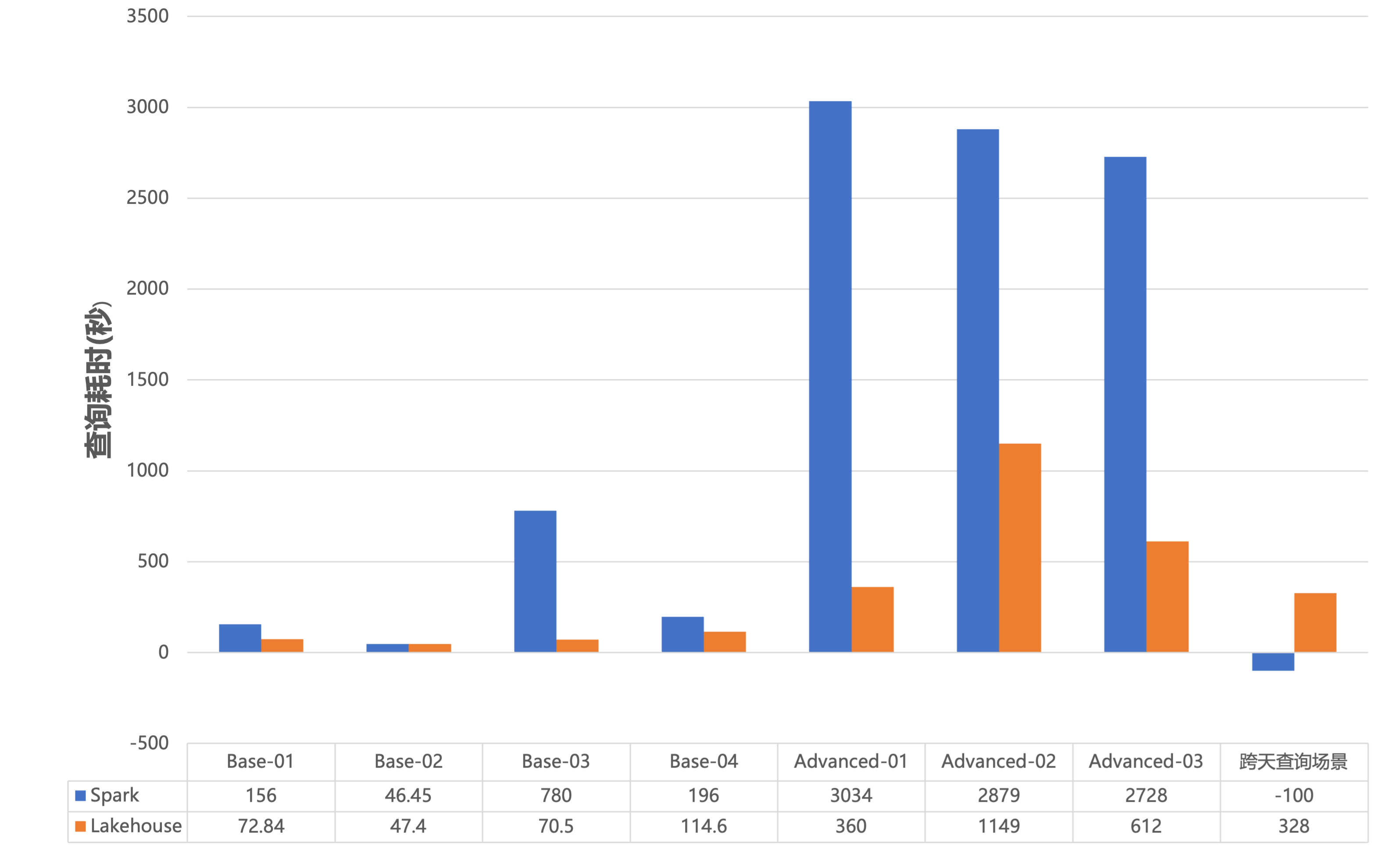
6) 查询优化。为了逐步提升即席查询的响应效率,云器科技还针对查询性能进行了大量优化,如查询计划优化、采用Share-everthing架构提高读写性能、算子优化、向量执行等,从而获得了查询性能的大幅提升。
在使用成本方面。新的数据平台在系统架构和技术上进行了多重创新和优化,为长安汽车大幅节省了数据存储、计算,以及平台运维的成本,减少了资源浪费,包括:
为了在汽车智能化时代建立一马当先的优势,给消费的人提供更优质的用车服务体验,长安汽车智能化研究院积极探索全新的数据平台方案以低成本支撑迅速增加的车联网数据处理,从而满足各项业务需求。通过采用云器科技的Lakehouse一体化数据平台产品,长安汽车实现了以下主要的效果与价值:
1) 系统具备了对超大规模数据的解决能力,还可以应对未来数据规模的进一步增长。通过采用一体化架构、创新的增量计算等技术,新的数据平台能够有效支撑高并发、大规模数据的写入和处理问题。长安汽车因此能应对未来数据规模的迅速攀升,并支撑2025年接入千万辆汽车数据的目标。
2) 突破多重技术瓶颈,数据查询分析的时效性得到一定效果保障。在信号数繁多,以及车联网数据存在很多特殊性的前提下,为保障业务场景越来越复杂,时效性越来来越高的查询需求。新的数据平台在一体化架构、增量计算的基础上,还进行大量创新,如MV on MV、数据去重、查询优化等,从而突破了超大规模数据即时查询、延迟数据处理、信号可变列等技术瓶颈,满足各类场景的即时查询需求。最终让客户服务更完善、响应更及时。
3) 提升开发效率、简化使用门槛。平台一体化的架构免去了长安汽车原先需对复杂的大数据组件来维护的工作;同时在新的平台中,用户都能够用一套SQL进行数据开发,以及系统基于MV on MV自动刷新数据处理链路,让整个数据开发工作变得更简单,业务协作更高效。从而扩展了长安汽车的数据分析和洞察能力。
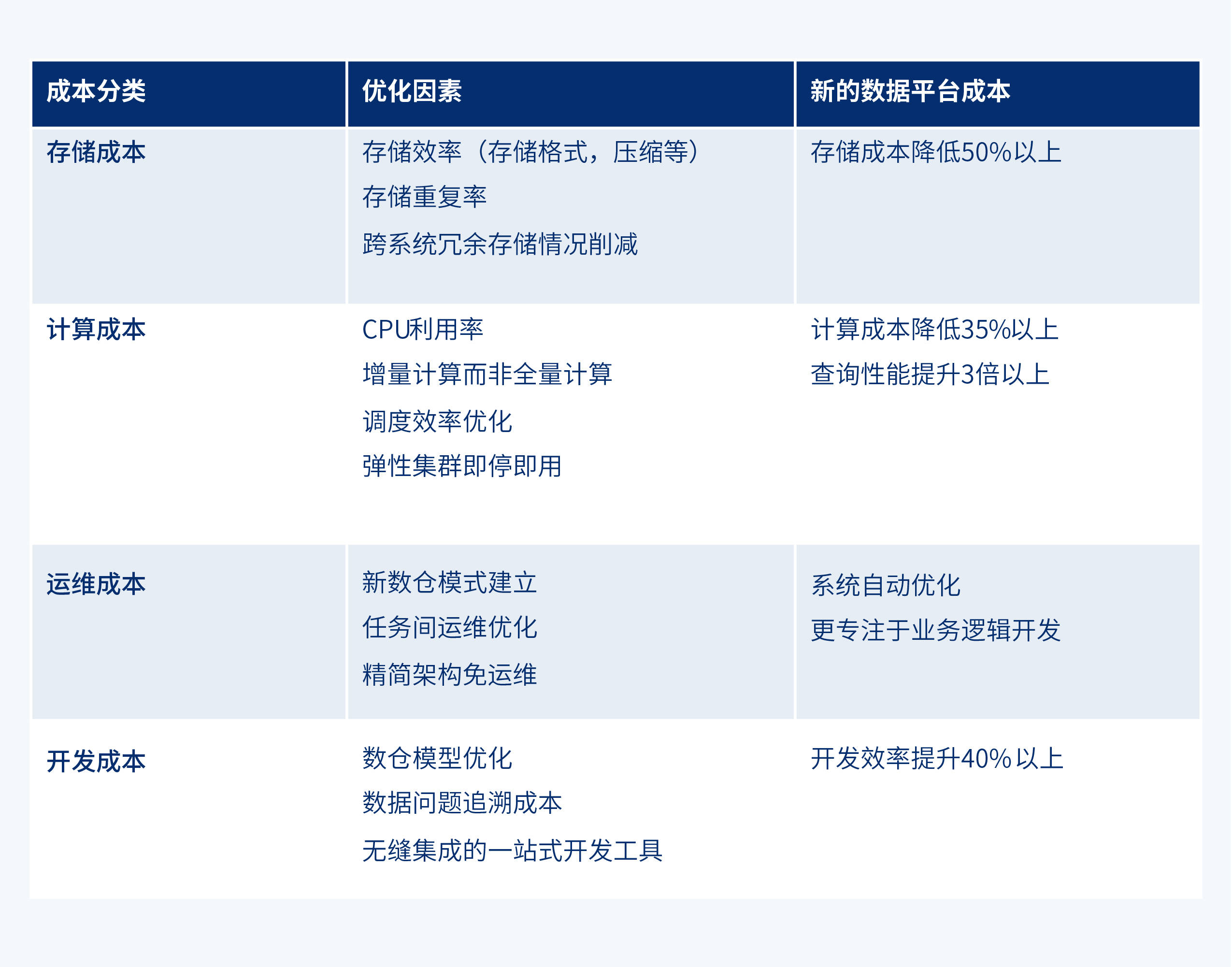
4) 存储和计算成本得以大幅度降低。在存储成本方面,通过采用更高效的数据存储方式和压缩算法,结合系统架构上优化,如一体化减少数据冗余,存算分离等,平台的存储成本降低了50%以上;在计算成本方面,通过优化的数据架构和高效的数据处理方案,平台的计算成本降低了35%以上;在开发和运维成本方面,平台采用一体化架构,并在多个数据处理流程中引入自动能力,让平台的开发和运维成本明显降低。此外,通过多种查询优化,平台的查询性能提升了3倍以上,减少计算时间的同时也节省了计算资源。最终有效缓解了长安汽车面对成本攀升的压力。
回顾大数据技术的演进历史,业内总是在跟随数据应用场景、数据类型和规模的变化,寻求在大数据技术架构、功能、性能、成本等方面更优解。如2005年左右诞生和发展的Hadoop技术体系,在互联网时代,曾为公司可以提供了一个以低成本高效处理大规模互联网数据的能力。
但在马上就要来临的物联网时代,物联网数据,尤其是其中由汽车智能化浪潮带来的海量车联网数据,有着多种显著区别于以往别的类型数据的特征。比如,一方面,车联网数据存在高并发,超大规模,以及价值密度低的特征,但业务场景又需要对这一些数据进行快速写入,全量计算;另一方面,车联网数据存在数据延迟、信号列可变,原始表过大等问题,但业务场景又要求能对复杂的数据来进行即时查询分析,满足业务上的时效性要求。
长安汽车与云器科技联合项目组在车联网数据处理领域进行的前沿探索经验表明,如果继续采用传统的大数据平台架构和技术来处理规模一直增长的车联网数据,以上问题不仅没办法得到根本解决,还会带来极其高昂的数据处理成本,最终也很快会制约业务的发展。因此,在马上就要来临的车联网时代,广大车企为了更好地实现汽车智能化的目标,就必须下定决心,拥抱新架构、新技术,如采用一体化架构、增量计算等技术,提升数据平台的扩展性、弹性、性能、和成本优化,从容应对车联网时代的数据处理挑战。
声明:本文由入驻搜狐公众平台的作者撰写,除搜狐官方账号外,观点仅代表作者本人,不代表搜狐立场。